

The Automation Assumption Was Wrong—The Revolution Eats Itself
As well as the 'Oh Sh**' moment for Knowledge Workers

Marc Benioff kicked off 2025 by announcing that Salesforce won’t be hiring any software engineers this year. On Joe Rogan, ‘new-look’ Mark Zuckerberg said he expects AI to automate mid-level engineers this year. A few days ago, Sam Altman pronounced,“Software engineering is going to look very different at the end of 2025.”
Across the industry, I’m hearing the same thing from founders: junior and mid-level engineers aren’t getting hired.
I’m old enough to remember when everyone told me to learn to code or risk obsolescence. (A depressing prospect for me—I like human languages, not Python or Java.)
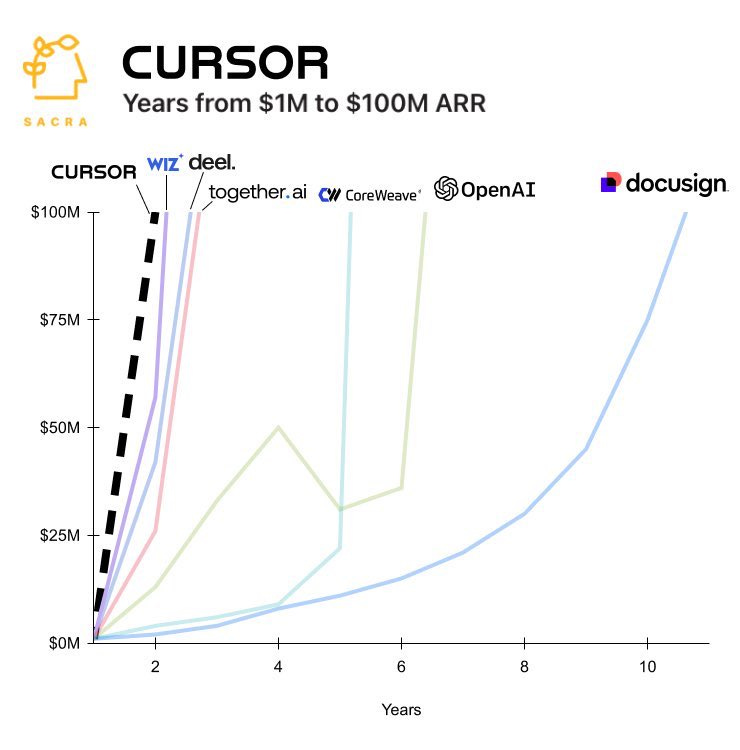
And yet, here we are: the fastest-growing application of all time isn’t ChatGPT (anymore), DeepSeek, or a social network—it’s Cursor AI, an AI-powered code editor. (Good news for me: ‘human’ is now the language of coding.)
AI is automating exactly the kind of knowledge work that conventional wisdom said would be safe. Software ate the world—now AI is eating software.
The revolution devours its own children.
DeepResearch: The ‘Oh Shit’ Moment
The next wave is obvious: law, banking, finance—any industry involving information retrieval, synthesis, and crucially, reasoning.
Consider DeepResearch, OpenAI’s latest feature, released this week. Currently, it’s only available to Pro Subscribers ($200/month). I’ve been trying to build my own research agent workflows for months, and now I’m wondering why I even bothered—because now there is something with far better functionality that actually works.
A Reddit post calling this the ‘Oh Shit’ moment for knowledge work sums it up perfectly:
“I dropped $200 on the Pro sub yesterday and I’m seriously blown away. This feature is crazy impressive—like, it’s probably better than 99% of analysts out there. If you’re in finance or consulting (or any strategy role), you NEED to check this out.
The research it delivers is super sophisticated. It digs into niche financial and business data that’s nearly impossible to find online. I’ve spent around $5,000 on similar analysis before, but this gem took just 21 minutes. And honestly, it feels the least AI-ish out there—no unnecessary fluff, just solid, high-quality work.”
It’s still early to quantify exactly how this shakes out, but you don’t need a crystal ball to see where this is going. It’s getting better. Quickly.
And now, we’re moving beyond knowledge retrieval and synthesis into something far bigger: AI isn’t just answering questions—it’s starting to reason.
Humanity’s Last Exam
Enter Humanity’s Last Exam (HLE).
Developed last year by Scale AI and the Center for AI Safety (CAIS), it’s designed to be the ultimate test of AI’s ability to reason at the highest human level across multiple disciplines.
HLE consists of 3,000 questions developed by nearly 1,000 contributors from over 500 institutions across 50 countries. It spans fields that demand completely different cognitive strengths: the precision of mathematics, the abstraction of philosophy, the strategic depth of law, the creativity of the humanities, and the problem-solving of the natural sciences.
Each question isn’t just difficult—it challenges Nobel Prize-winning minds and those with Einstein-level IQs. No single person could solve them all.
By design, HLE is a direct test of the classic AI-skeptic argument: that AI, at its core, is simply a prediction machine—fancy autocomplete.
As skeptics claim, AI might structure knowledge, assemble insights, and make expertise more accessible—but it can’t actually reason. After all, true intelligence isn’t just about knowing things—it’s about making connections, breaking down complex problems, and generating new ideas.
***
Given the breakneck pace of 2025—trillion-dollar market swings, political orthodoxies shifting overnight and trade wars—it would be easy to miss this story.
But something very interesting is happening with HLE.
When it launched in April 2024, AI struggled. GPT-4o, Grok-2, Claude 3.5 Sonnet, and OpenAI O1—the most advanced models at the time—barely scraped by with 10% accuracy.
So far, advantage team fancy autocomplete.
But in 2025, with the advent of new ‘reasoning models’ increasingly trained with reinforcement learning (RL)*, we’re hitting an exponential curve. DeepResearch—released just last week—has already taken us from 10% accuracy to 30%!
*Side note: I’ll write more on what’s happening with RL next week.
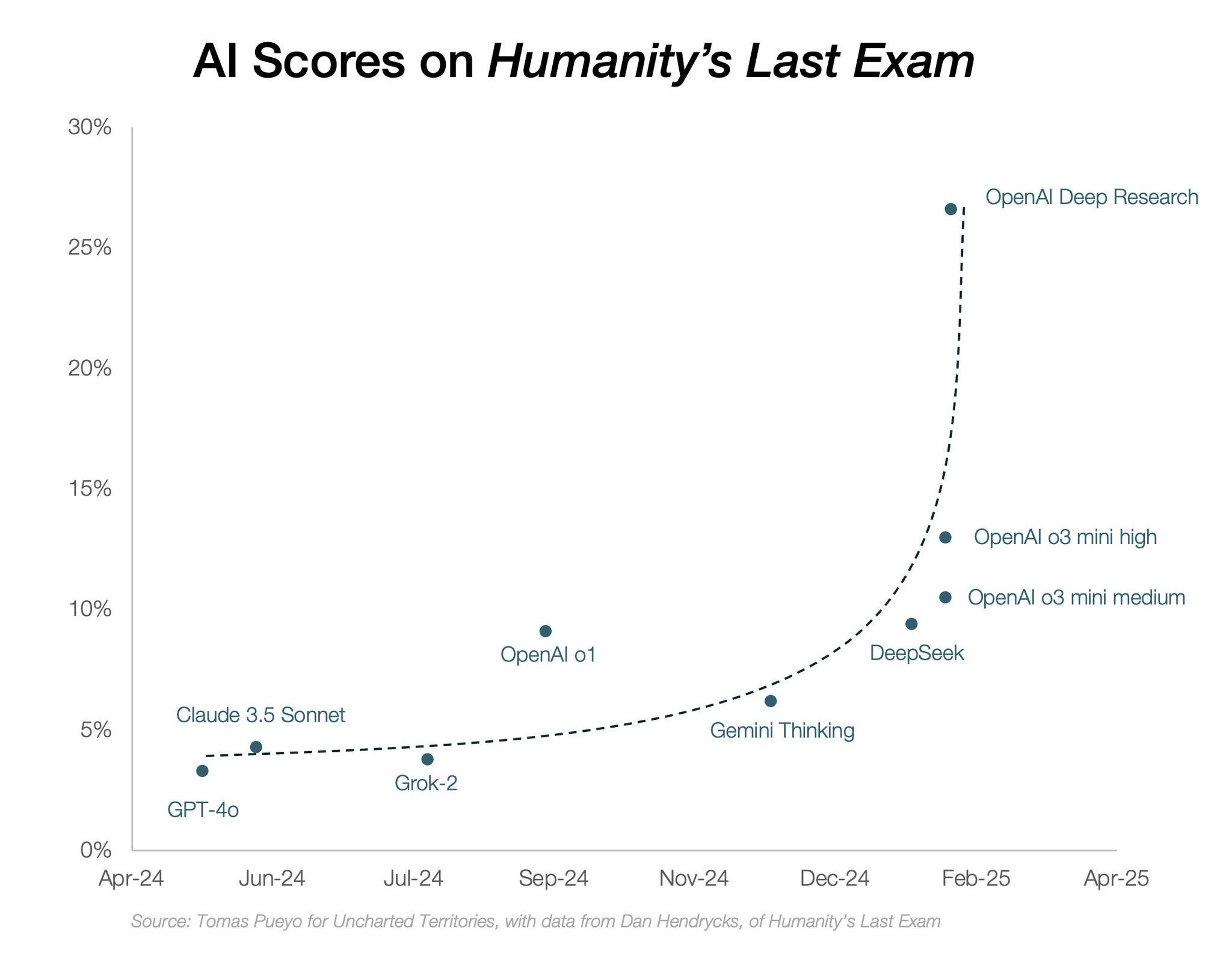
Oh shit! Maybe AI is more than a stochastic parrot after all.
If this curve continues, we will hit 100% before the year is out. And if that trajectory holds, AI will soon surpass human reasoning altogether.
This forces us to confront a far deeper philosophical truth:
If AI is beginning to excel at the ceiling of human-level reasoning—not just in mathematics or coding, but in law, philosophy, and creative problem-solving—then we are no longer talking about automation, or even intelligence augmentation.
We are talking about AI developing its own cognitive edge—thinking better than humans, across every field.
Could this be the dawn of unbounded knowledge?
Next week, I’ll go deeper—starting with a breakdown of advanced reasoning models (TL;DR: RL and compute are converging), why history may no longer be a useful guide, and the new philosophical frames we need to grasp where this is headed. (Hint: David Deutsch’s Beginnings of Infinity.)
For now—namaste.
Hat tip for “stochastic parrot”
I will die grateful in the knowledge that I never spent one millisecond of my precious time on earth “learning how to code” :-)